I "maskinelæring", det Support Vector Machine (SVM) er en overvåget læringsmodel med tilknyttede algoritmer, der analyserer data og genkender mønstre, der bruges til klassificering og regressionsanalyse i Business Intelligence. Det SVM Basic tager et sæt inputdata og forudsiger for hver given input hvilken af de to klasser af output hører hjemme, så det er en binær lineær ikke-probabilistisk klassifikator (vælg bare mellem 2 muligheder). Givet et sæt træningseksempler, hver markeret som tilhørende en af to kategorier, bygger en træningsalgoritme en model, der tildeler nye eksempler i en kategori eller andet. Denne type model bruges i vid udstrækning til analyse af modeller, hvor et datasæt kun skal klassificeres i to kategorier, svig eller nej-svindel, ja eller nej til kredit osv. En SVM-model er en repræsentation af eksemplerne (database, hvor estimeringen blev udført) som punkter i rummet, således at tildele eksempler på separate kategorier, der generelt er opdelt med et defineret rum, rum, der skal være så bredt som det er muligt. De nye inputdata klassificeres i samme rum og forudsiger, hvilken kategori de tilhører.
Supportvektormaskinen det er baseret på det faktum, at hver nye data kan klassificeres inden for den tilsvarende kategori baseret på indlæringen af de analyserede data. I eksemplet nedenfor tilhører objekterne kun en klasse, enten grøn eller rød. Adskillelseslinjen definerer en grænse på højre side, hvor alle objekter er grønne og til venstre, hvor alle objekter er røde.
Annoncer

I dette andet eksempel kan vi observere de to kategorier divideret med en central akse og to afstandsafstand mellem dem.
Annoncer
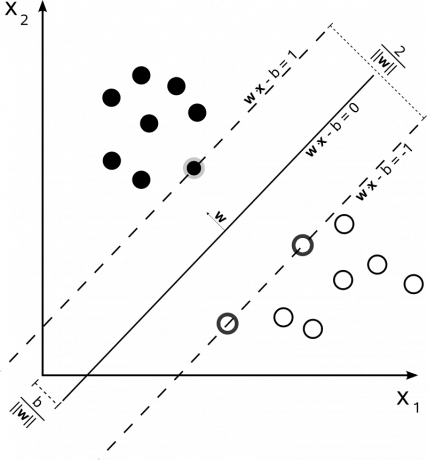
I det virkelige liv er det meget vanskeligt at finde modeller så klare som dem på disse billeder, men det er altid muligt at have en tilnærmelse.
Annoncer


