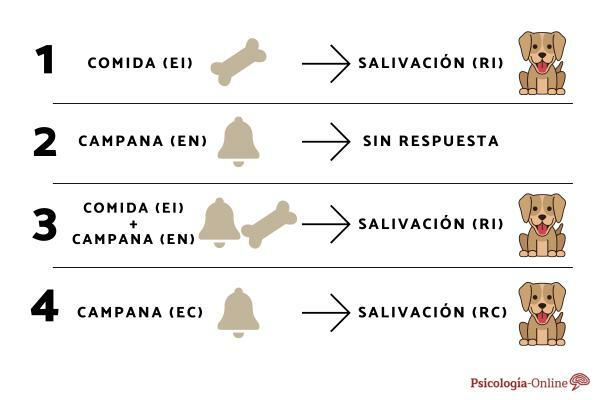
En test er en videnskabeligt instrument for så vidt det måler, hvad det hævder, dvs. det er gyldigt, og det måler godt, det vil sige det er nøjagtigt eller pålideligt. Hvis vi finder et instrument, som vi ikke kan stole på de målinger, de leverer, da de varierer fra tid til anden, når vi måler det samme objekt, så vil vi sige, at det ikke er pålideligt. Et instrument til at måle korrekt Noget skal være præcist, for hvis ikke måler du det, du måler, måler du det forkert. Derfor er det en nødvendig, men ikke tilstrækkelig betingelse at være præcis. Derudover skal det være gyldigt, det vil sige, hvad det måler med præcision vil være, hvad det er beregnet til at måle, og ikke noget andet.
Absolut og relativ pålidelighed: Vi kan nærme os problemet med pålideligheden af en test på to forskellige måder, selvom de stort set falder sammen.
Pålidelighed og unøjagtigheden af dens målinger: Når et emne reagerer på en test, opnår han en empirisk score, der påvirkes af en fejl. Hvis der ikke var nogen fejl, ville motivet få sin sande score. Testen er upræcis, fordi den empiriske score ikke svarer til den sande sande score. Denne forskel mellem de to scores er prøveudtagningsfejlen, målefejlen. Det
Målingers pålidelighed og stabilitet: En test vil være mere pålidelig, jo mere konstant eller stabil de resultater, den giver, opretholdes, når den gentages. Jo mere stabile resultaterne er ved to lejligheder, jo større er sammenhængen mellem dem. Denne sammenhæng kaldes pålidelighedskoefficient. Dette fortæller os, ikke størrelsen af fejlen, men testens sammenhæng med sig selv og konsistensen af de oplysninger, den tilbyder. Det pålidelighedskoefficient udtrykker den relative pålidelighed af testen.
Pålidelighedskoefficienten og pålidelighedsindekset: - Pålidelighedskoefficient af en test er korrelationen af testen med sig selv, opnået for eksempel i to parallelle former: rxx. - Præcisionsindekset er sammenhængen mellem en tests empiriske scores og dens sande scores: rxv Præcisionsindekset altid vil være større end pålidelighedskoefficienten For at finde ud af pålidelighedskoefficienten skal disse tre metoder fremhæves klassikere:
- Find sammenhængen mellem testen og dens gentagelse: Gentagelsesmetoden eller test-retest-metoden: Den består af anvende den samme test på den samme gruppe to gange og beregne sammenhængen mellem de to serier af scorer. Denne sammenhæng er pålidelighedskoefficienten. Denne metode giver normalt en højere pålidelighedskoefficient end dem, der opnås ved andre procedurer, og kan være forurenet af forstyrrende faktorer.
- Find sammenhængen mellem to parallelle former for testen: Metoden til parallelle former: To former forberedes parallelle linjer i den samme test, det vil sige to ækvivalente former, der giver den samme information og anvendes på den samme gruppe af emner. Korrelationen mellem de to former er pålidelighedskoefficienten. Ved ikke at gentage den samme test undgås forstyrrende kilder til retest-pålidelighed ved denne metode.
- Find korrelationen mellem to parallelle halvdele af testen: Metoden med to halvdele: Testen er opdelt i to ækvivalente halvdele, og korrelationen mellem dem findes. Det er den foretrukne metode, da den er enkel og undgår begrænsningerne i de tidligere procedurer. Du kan vælge de ulige elementer i testen for at udgøre den ene halvdel og de lige dele for at udgøre den anden.
Pålidelighedskoefficienten og sammenhængen mellem parallelle tests
Det pålidelighedskoefficient af en test indikerer det forhold, at den sande varians er af den empiriske varians: graf33 Pålidelighedskoefficienten for en test varierer mellem 0 og 1. For eksempel: hvis korrelationen mellem to parallelle tests er rxx´ = 0'80, betyder det, at 80% af variansen af testen skyldes det sande mål, og resten, dvs. 20% af variansen af testen skyldes fejl. Det pålidelighedsindeks af en test er sammenhængen mellem dens empiriske scores og dens sande score pålidelighedsindeks = Pålidelighedsindekset er lig med kvadratroden af pålidelighedskoefficienten
Når der er udviklet to parallelle former for en test, anvendes variansanalyseproceduren for at kontrollere afvigelsens homogenitet og forskellen mellem målene. Hvis afvigelserne er homogene, er forskellen mellem midlerne ikke signifikant, og de to former er konstrueret med det samme antal elementer af samme type og psykologisk indhold, kan det siges, at de er parallel. Hvis ikke, skal du reformere dem, indtil de er det. Manglen på pålidelighed identificeres med værdien rxx´ = 0 4. - Den typiske målefejl: Forskellen mellem den empiriske score og den sande er den tilfældige fejl, kaldet målefejl. Standardafvigelsen for målefejl kaldes standardmålefejl. Det standard målefejl gør det muligt at foretage skøn over testens absolutte pålidelighed, det vil sige estimere, hvor meget målefejl påvirker en score.
Pålidelighed og længde: Testens længde refererer til antallet af dens elementer. Dens pålidelighed afhænger af denne længde. Hvis en test består af tre elementer, kan et individ opnå en score på 1 ved den ene lejlighed og en score på 1 på den anden eller parallelt.
Fra en lejlighed til en anden har resultatet varieret med et point; et punkt ud af tre er en 33% variation, en høj variation. Hvis forsøgspersonerne får utilsigtede variationer af denne type, vil korrelationen af testen med sig selv eller den for de to parallelle former for testen blive kraftigt nedsat og kan ikke være høj. Hvis testen er meget længere, hvis den for eksempel har 100 elementer, kan et emne opnå 70 point ved en lejlighed og 67 på en parallel måde. Fra den ene tid til den anden har den varieret 3 point; det er en relativt lille varians i forhold til den samlede test, specifikt 3%. Disse små utilsigtede ændringer af denne størrelse, som forekommer i scoringen af emnerne, når de går fra en parallel form, er relativt uvigtige og falder ikke så meget som før korrelationen mellem begge.
Pålidelighedskoefficienten vil være meget højere end i det foregående tilfælde. Spearman-Brown ligningen udtrykker forholdet mellem pålidelighed og længde. Præcisionen for en test er nul, når længden er 0, og den stiger, når længden øges. Selvom stigningen er relativt mindre, da længden på delen er større. Det betyder, at præcisionen vokser meget i starten og relativt mindre bagefter. Når længden har en tendens til uendelig, har pålidelighedskoefficienten tendens til at
Efterhånden som testets længde øges, øges dens præcision, fordi den sande varians stiger med en højere hastighed end fejlvariansen. Dette betyder, at testens nøjagtighed stiger, fordi variationen på grund af fejlen falder. Rulon-formlen såvel som Flanagan- og Guttman-formlen er især anvendelig ved beregning af pålidelighedskoefficienten ved hjælp af metoden med to halvdele. Disse er formler, der bruges til at beregne pålidelighedskoefficienten.
Pålidelighed og konsistens: Pålidelighedskoefficienten kan også findes på en anden måde, kaldes det alfa-koefficient eller generaliseringskoefficient eller repræsentativitet (Cronbach). Denne alfakoefficient angiver, hvor nøjagtigt nogle emner måler et aspekt af personlighed eller adfærd. Det kan fortolkes som: Et skøn over den gennemsnitlige korrelation af alle mulige emner i et bestemt aspekt. Et mål for testens nøjagtighed baseret på dens sammenhæng eller interne konsistens (indbyrdes sammenhæng mellem dens elementer; i hvilket omfang testemnerne alle måler det samme) og deres længde. Angivelse af testens repræsentativitet, det vil sige den mængde, i hvilken stikprøven, der komponerer den, er repræsentativ for populationen af mulige genstande af samme type og psykologisk indhold. Det alfa-koefficient Det afspejler hovedsageligt to grundlæggende begreber i testens præcision: 1. Sammenhængen mellem dets elementer: i hvilket omfang de alle måler den samme ting godt.
Testens længde: ved at øge antallet af tilfælde i en prøve, og hvis fejl elimineres systematisk repræsenterer prøven bedre den population, hvorfra den er trukket, og afslappet fejl. Hvis testelementerne er dikotome (ja eller nej, 1 eller 0, er enige eller uenige osv.), Er ligningen af alfakoefficienten forenklet, hvilket giver anledning til ligningerne af Kuder-Richardson (KR20 og KR21). I betragtning af et bestemt antal ting vil en test være jo mere pålidelig, jo mere homogen er den. Alfakoefficienten fortæller os pålideligheden, for så vidt som den repræsenterer homogenitet og sammenhæng eller intern konsistens af elementerne i en test.
Ifølge vareprøvepladsmodellen er formålet med testen at estimere det mål, der ville opnås, hvis alle emnerne i prøveområdet blev brugt. Denne måling ville være den sande score, som er omtrent tæt på de faktiske målinger. Afhængig af i hvilken grad en prøve af emner korrelerer med den sande score, er testen mere eller mindre pålidelig. Centralt i denne model er korrelationsmatricen mellem alle elementerne i prøveområdet. Denne prøvemodel insisterer mere direkte på intern konsistens, og i det omfang den opnår den, garanterer den indirekte stabilitet.
Den lineære model for parallelle tests insisterer mere på scoreens stabilitet, og i det omfang den opnår stabilitet, favoriserer den indirekte intern konsistens. Hvis vi anvender en test for at etablere individuelle diagnoser og prognoser, skal pålidelighedskoefficienten være 0,90 opad. I prognoser og kollektive klassifikationer er kravet ikke så stort, selvom det ikke er praktisk at afvige for langt fra 0,90 til 0,80.
Nogle gange er det vanskeligt at opnå koefficienter på mere end 0,70 i visse typer tests, såsom personlighedstests. Hvis de parallelle former eller parallelle halvdele anvendes efter et mere eller mindre stort interval, kan chancefejlene være mere talrige end dem, der påvirker alfakoefficienten. Dette skyldes, at det, der sænker korrelationen, ikke kun er tilfældige fejl, der er iboende for testen og ved en enkelt lejlighed, som er dem, der tages i betragtning alfa-koefficienten, men også alle de fejl, der kan komme fra de to forskellige situationer, som kan variere i mange detaljer, indflydelse. Derfor er alfa-koefficienten normalt højere end de andre koefficienter.
Med undtagelse af koefficienten fundet ved gentagelse af den samme test, da der er større sandsynlighed for, at fejlene tilfældige mønstre fra den første applikation gentages i den anden, og i stedet for at mindske korrelationen mellem de to, øge. Man skal sørge for, at den anden ansøgning er fuldstændig uafhængig af den første. Hvis vi opnår dette, vil dette være den nemmeste og billigste metode og tilrådelig, når vi prøver at forstå stabiliteten af scorerne, især i lange perioder og med komplekse tests. > Næste: Testernes gyldighed